Качество оптимизации или мегагерцы, спрессованные в стрелу времени
Компилировать надо компилятором, а оптимизировать — головой. Оптимизирующий компилятор увеличивает скорость программы главным образом за счет того, что выбивает из нее весь shit. Чем качественнее исходный код, тем меньший выигрыш дает оптимизатор, которому остается всего лишь заменять деление умножением (а само умножение логическими сдвигами) и планировать потоки команд. "Четверки" и первые модели Пней имели довольно запутанный ритуал спаривания и для достижения наивысшей производительности машинные инструкции приходилось радикально переупорядочивать, причем расчет оптимальной последовательности представляет собой весьма нетривиальную задачу, благодаря чему качество оптимизации разнилось от одного компилятора к другому. Но с появлением Pentium Pro/AMD K5 эта проблема сразу стала неактуальной — процессоры поумнели настолько, что научились переупорядочивать машинные команды самостоятельно и интеллектуальность оптимизирующих компиляторов отошла на второй план.
Не стоит право же, гнаться за новыми версиями оптимизаторов. Эта технология достигла своего насыщения уже в середине девяностых и никаких прорывов с тех пор не происходило. Поддержка мультимедийных SSE/3DNow! команд воздействует только на мультимедийные и отчасти математические приложения, а всем остальным от нее ни жарко, ни холодно. Кривую от рождения программу оптимизатор все равно не исправит (он ведь не бог), а грамотно спроектированный код равномерно распределяет нагрузку по всем функциональным узлам и без острой необходимости лучше его не ускорять. Возьмем сетевое приложение. Оптимизация программного кода увеличивает количество обрабатываемых запросов, что в свою очередь увеличивает нагрузку на сеть, и общая производительность не только не возрастет, но может даже упасть.
Агрессивные алгоритмы оптимизации (за которые обычно отвечает ключ ?O3) или, правильнее сказать "пессимизации", зачастую дают прямо противоположный ожидаемому результат. Увлеченные "продразверсткой" циклов и функций они ощутимо увеличивают объем программного кода, что в конечном счете только снижает производительность.
А глюки оптимизции? Впрочем, о глюках мы уже говорили.
Не гонитесь за прогрессом (а то ведь догоните), но и не превращайте верность традициям в религиозный фанатизм. Глупо отказываться от "лишней" производительности, если компилятор дает ее даром. Создатели GCC говорят о 30% превосходстве версии 3.0 над 2.95, однако, далеко не все разработчики с этим согласны. Большинство вообще не обнаруживает никакого увеличения производительности, а некоторые даже отмечают замедление. Ничего удивительного! Алгоритмы оптимизации в GCC 3.x претерпели большие изменения. Одни появились, другие исчезли, так что в целом ситуация осталось неизменной. Только вот про поддержку новых процессоров не надо, а? С планированием кода они справляются сами и самостоятельно (учет особенностей их поведения дает считанные проценты производительности, да и то на чисто вычислительных задачах), а новые векторные регистры и команды просто так не задействуешь. Одной перекомпиляции здесь недостаточно. Программный код должен использовать эти возможности явно. Эффективно векторизовать код пока не умеют даже суперкомпьютерные компиляторы. Во всяком случае пока. Или точнее уже.
А что насчет сравнения 32-разядного кода с 64-разрядным? Пользователь думает: 64 намного круче, чем 32, а, следовательно, и быстрее! Начинающий программист: ну, может, и не быстрее (все равно все тормозит ввод/вывод), но что не медленнее — это точно! А вот хрен вам! Бывалые программисты над этим только посмеиваются. Медленнее! Еще как медленнее! 32-разрядный код по сравнению с 16-разрядным в среднем потребляет в 2 —2.5 раза больше памяти. 64-разрядный код — это вообще монстр, разваливающийся под собственной тяжестью. А ведь размер кэш-буферов и пропускная способность системной шины не безграничны! "Широкая" разрядность дает выигрыш лишь в узком кругу весьма специфических приложений (большей частью научных). Скажите, вам часто приходится сталкиваться с числами порядка 18.446.744.073.709.551.615? Тогда с какой стати ждать ускорения?
Данные, полученные Тони Бруком (Tony Bourke) c www.OSnews.com (см. рис.1), это полностью подтверждают (http://www.osnews.com/story.php?news_id=5830&page=1). GCC 2.95.3 генерирует чуть- чуть более быстрый код, чем GCC 3.3.2, а 64-битная версия GCC 3.3.2 находится глубоко в заднице и конкретно тормозит. Сановский компилятор рулит и в обоих случаях, но 64-разрядный код все равно много медленнее.
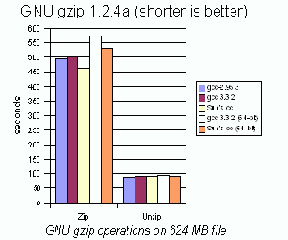
Рисунок 1 сравнение качества кодогенерации различных компиляторов на примере утилиты GZIP (лучшему результату соответствует меньшее значение).
Только не надо говорить, что мы выбрали "неудачный" пример для сравнения! GZIP – типичное системное приложение и на большинстве остальных результат будет таким же. Мультимедийные и математические приложения при переходе на GCC 3.x могут ускорить свою работу в несколько раз и упускать такой выигрыш нельзя. Жаба задушит. Но какую версию выбрать? "Новое" еще не означает "лучшее", а неприятную тенденцию ухудшения качества кодогенерации у GCC мы уже отмечали.
Тестирование показывает, что пальма первенства принадлежит GCC 3.2.3, а GCC 3.3 и GCC 3.2.0 на несколько процентов отстают по скорости (см .рис. 2, 3). Вроде бы мелочь, а как досадно! Если GCC 3.2.3 отсутствует в портах вашего дистрибьютива — не расстраивайтесь! Вы не многое потеряли! Ставьте любую стабильную версию семейства 3.х и наслаждайтесь жизнью. Специально вытягивать из сети GCC 3.2.3 никакого смысла нет. Если вам действительно нужна производительность — переходите на ICC. Практически все, перекомпилировавшие мультимедийные приложения, подтвердили 20%-30% ускорение по сравнению с GCC 3.х. Целочисленные приложения в обоих случаях работают с той же скоростью или даже чуть медленнее (особенно, если программа была специально заточена под GCC). На процессорах фирмы AMD ситуация выглядит иначе и GCC 3.3 с ключиком ?mcpu=cpu-type athlon генерирует на 30%-50% более быстрый код чем ICC 8.1.
Речь, разумеется, идет только о векторных операциях, а на целочисленных ICC по прежнему впереди.
Приплюснутые программы главным образом выигрывают от того, что у ICC более мощная STL, оптимизированную под Hyper Threading, однако, на классический Си эта льгота не распространяется и такие приложения лучше всего компилировать старым добрым GCC 2.95. Исключение, пожалуй, составляет программы, интенсивно взаимодействующие с памятью. Оптимизатор ICC содержит специальный алгоритм, позволяющий ему выхватить несколько дополнительных процентов производительности за счет за счет механизма предварительной выборки и учета политики кэш-контроллера первого и второго уровней (подробности можно найти в моей книге "Техника оптимизации — эффективное использование памяти").

Рисунок 2 сравнение качества кодогенерации по данным теста ROOT (имитатор финансовых приложений). Большее значение — лучшая скорость.

Рисунок 3 сравнение качества кодогенерации по данным теста GEANT4 (моделирование движения элементарных частиц). Большее значение — лучший результат
